Flink1.11.0源码手动编译包 编译步骤详见:https://blog.csdn.net/dzh284616172/article/details/107571972
”flink flink-1.11.0 flink源码编译 maven项目编译 大数据“ 的搜索结果
第1章 下载flink源码 官网: https://flink.apache.org/ https://flink.apache.org/zh/ Flink因为阿里的加入,对国内IT人员变得越来越友好了,官网也出了中文版,也有很多中文文档了。 第2章 准备环境 2.1.Jdk...
1.下载代码,2.进入目录分别执行执行命令
Maven坐标:org.apache.flink:flink-metrics-core:1.13.2; 标签:apache、flink、metrics、core、中文文档、jar包、java; 使用方法:解压翻译后的API文档,用浏览器打开“index.html”文件,即可纵览文档内容。 ...
Flink本身包含系统运行所需的类和依赖项,如协调、网络、检查点、故障转移、操作、资源管理等 <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-core</...

macos M1编译Flink 源码问题 一、flink编译flink-runtime-web出现Failed to execute goal com.github.eirslett:frontend-maven-plugin Failed to execute goal ...

命令,因为 编译的时候 会使用 某些 test 类型的依赖,而 -Dmaven.test.skip=true 命令是不会生成这些 test 依赖,编译出错。-DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-...
目录(1)Flink Stream与Kafka的集成(2)Flink SQL与Kafka的集成(2.1)第一步:Flink SQL Client配置好(2.2)第二步:创建hiveConfDir(2.3)第三步:测试Flink SQL与Kafka集成的代码(2.4)第四步:测试kafka...
我的问题类似于Unable to compile and create .avro file from .avsc using Maven我已经尝试了所有可能的东西,检查maven项目100次,仍然我无法运行avro-maven插件来生成我的avsc文件的代码.我下载了上面的maven项目,...
使用的是 scala 版本的flink (flink1.11.0)依赖 <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</...
扫一扫加入大数据公众号和技术交流群,了解更多大数据技术,还有免费资料等你哦 简介 对于单个flink任务提交到yarn集群,通过命令行的方式是能接受的,但是我们开发实时计算平台就需要通过代码的方式将我们...


解决flink打包失败
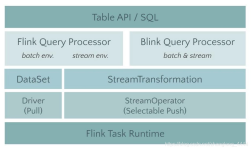
本文按照 flink 官网翻译整理,内容十分全面。
Flink SQL案例实践(1.11.0) 1. 背景 2020年随着阿里flink 批流一体大会开展,更多人和公司知道了flink的强大以及业务场景下的实际表现.关注和使用flink的公司以及个人会越来越多 在大数据领域,一个引擎可以同时支持...


第30讲:Flume 和 Kafka 整合和部署 Flume 概述 Flume 是 Hadoop 生态圈子中的一个重要组件,在上一课时中提过,它是一个分布式的、高可靠的、高可用的日志采集工具。 Flume 具有基于流式数据的简单灵活的架构,同时...
Flink1.11编译 注意 编译一定要用root用户编译,否则会出现各种乱七八糟的错误。我就是因为没用root差点精神崩溃,浪费好长时间。 版本 版本: flink-release-1.11.0-rc4 hadoop.version=2.6.0-cdh5.15.1 从pom文件...
1. 创建Flink项目及依赖管理 1.1创建Flink项目 官网创建Flink项目有两种方式: https://ci.apache.org/projects/flink/flink-docs-release-1.11/dev/projectsetup/java_api_quickstart.html 方式一: mvn ...




支持 Hadoop 3.0 及更高的版本:Flink 不再提供任何flink-shaded-hadoop-依赖。用户可以通过配置 HADOOP_CLASSPATH 环境变量(推荐)或在 lib 文件夹下放入 Hadoop 依赖项。另外include-hadoopMaven profile 也已经被...
要使用 Apache Flink 对 PostgreSQL 数据进行 CDC (change data capture, 数据变更捕获) 消费,你需要在你的项目中添加以下 Maven 依赖: <dependency> <groupId>org.apache.flink</groupId> &...
推荐文章
- 力扣——206.反转链表_力扣链表反转-程序员宅基地
- 如何解决深度冲突(Z-fighting),画面闪烁的问题-程序员宅基地
- Android 第三方库--2017年Android开源项目及库汇总_panel.travel-tv.top-程序员宅基地
- adb链接模拟器_adbconnect连接模拟器-程序员宅基地
- Python绘图Matplotlib手册-程序员宅基地
- lego-loam阅读理解笔记 一_horizon_angle = atan2(p.x, p.y) * 180.0 / m_pi;-程序员宅基地
- 购物车功能测试用例测试点整理思维导图方式_购物车测试点思维导图-程序员宅基地
- 使用matplotlib绘图实现动态刷新(动画)效果_matplotlib 动态刷新-程序员宅基地
- Apache Kafka 可视化工具调研_kafka-console-ui-程序员宅基地
- 如何编译部署独立专用服务端(Standalone Dedicated Server)【UE4】_ue4 独立服务器搭建-程序员宅基地